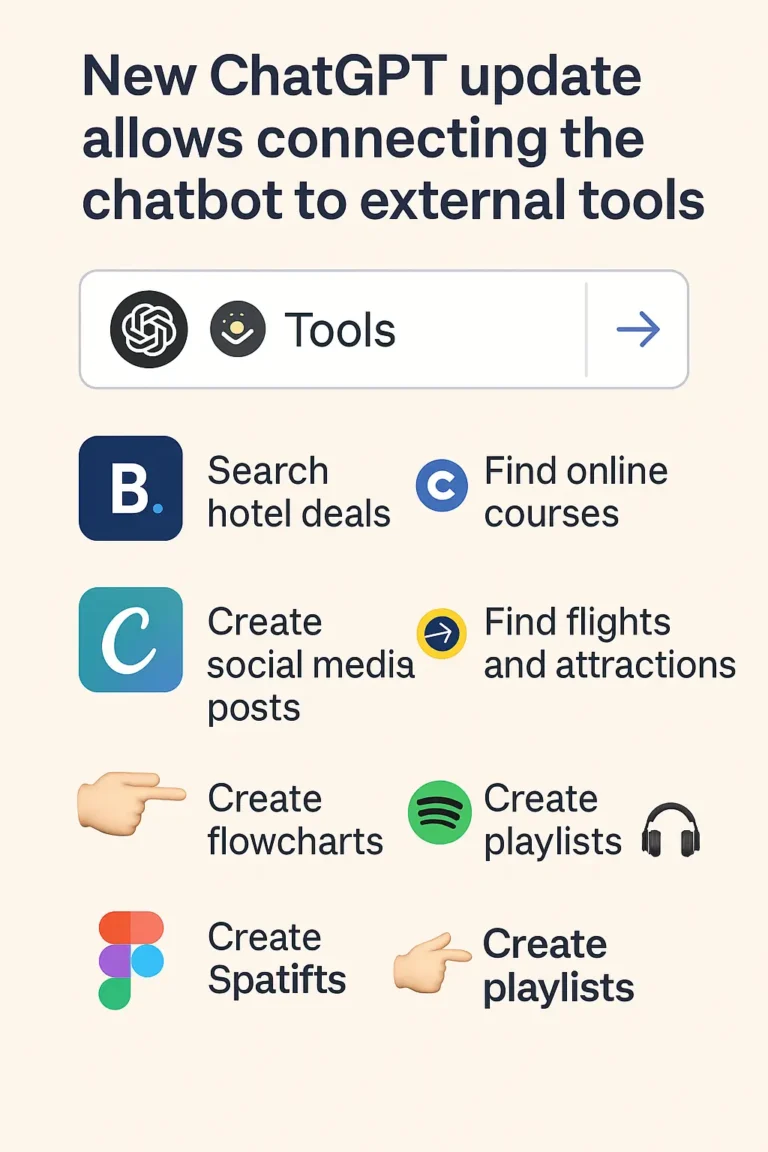
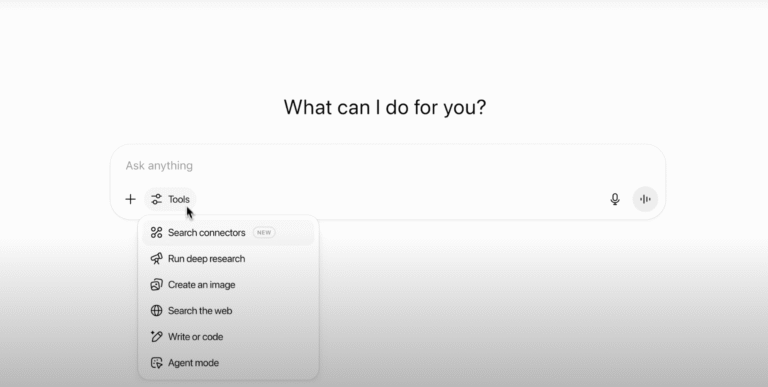
Explore topics
Browse the subjects TuningTalks covers most.
Use category pages to jump directly into the parts of AI you care about, from model releases to practical tool updates.
Stay current
Follow the latest model launches and product changes.
The redesigned homepage keeps new stories easy to scan on both desktop and mobile without burying them under sidebars and long archive lists.
Subscribe
Get new AI stories in your inbox.
If you already have a newsletter tool, this section can connect to it. If not, it still gives readers a clear next step after browsing.