
YouTube Rolls Out AI Hosts in Music App: The New Gemini-Powered DJ Experience
With YouTube Labs, Google adds conversational AI hosts between songs—bringing commentary, trivia, and radio flair to your playlists. By AI...
With YouTube Labs, Google adds conversational AI hosts between songs—bringing commentary, trivia, and radio flair to your playlists. By AI...

ChatGPT loosens restrictions with a bold new policy, sparking debate over AI intimacy, safety, and content moderation By AI Trend...
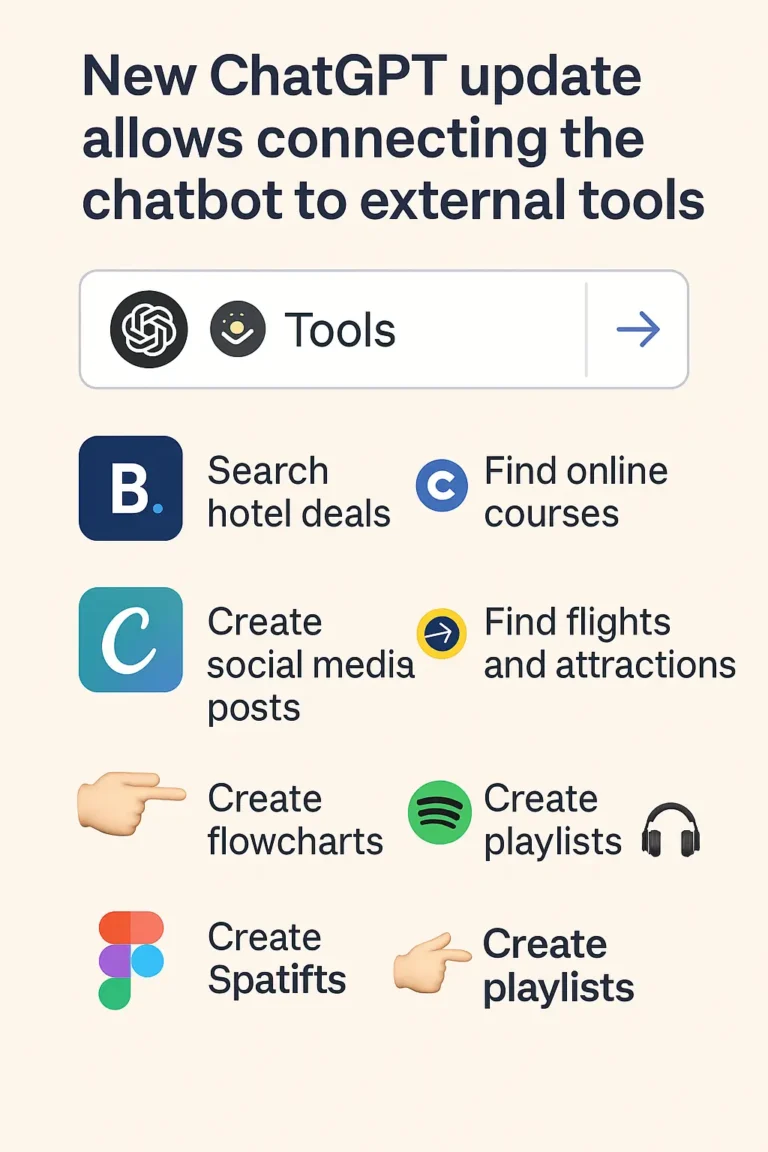
A major new update from OpenAI has just landed, and it’s a game changer: ⬆️ You can now connect ChatGPT...

Claude, the smart AI assistant, has just introduced a new feature that could truly change the way you work –...

Google has just released something that feels like Photoshop on steroids – the Nano Banana model in Gemini. The more...

🔍 Intro: A Wild Bid No One Saw Coming In one of the boldest moves yet by an AI startup,...

On August 7, 2025, OpenAI officially rolled out GPT-5, calling it the most capable and reliable version of its language...

Published: 29 July 2025Reading time: 4 min Tesla and Samsung have confirmed a $16.5 billion, decade-long pact for Samsung’s new...
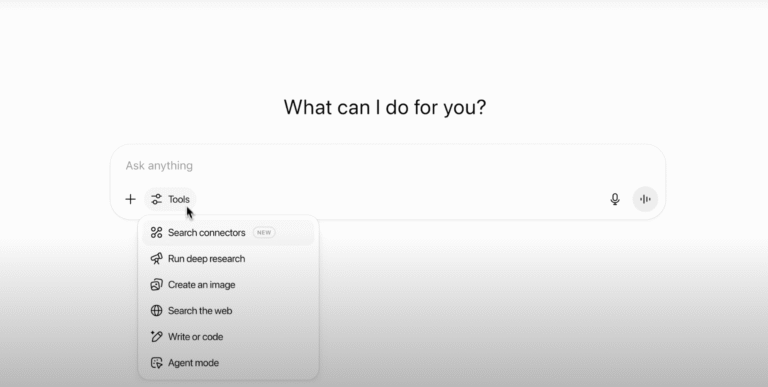
TL;DR Key Takeaways• OpenAI’s new Agent mode lets ChatGPT browse the web, click buttons, run code and fire off emails...